AIチャットボットの開発でデータ作成に悩んでいませんか?今回は、Builder.ioがオープンソース化した「GPT Crawler」を使って、指定したURLから簡単にGPTsを作成する方法をご紹介します。
GPTsを作る時に困るのがデータの作成ですが、このGPT Crawlerを使うとなんとURLを指定するだけでサイトをクローリングしてGPTsに最適なJSONデータを生成してくれます。
GPT Crawlerとは?
GPT Crawlerは、指定したURLをクローリングし、GPTsに最適なJSONデータを自動生成してくれるツールです。これにより、データ作成の手間を大幅に削減できます。
実践:弊社コーポレートサイトで試してみた
今回は、弊社 MAKE A CHANGE のコーポレートサイトを学習したGPTsを作成しました。
このチャットボットに質問すると、株式会社MAKE A CHANGEに関する情報を即座に提供してくれます。

作成手順
手順は以下3ステップです。
- ①GPT Crawlerをローカル環境に構築
- ②パラメーターをセットしてGPT Crawlerを実行
- ③生成されたファイルをGPTsに設定
順番に解説していきます。
①GPT Crawlerをローカル環境に構築
まずGitからオープンソース化されたGPT CrawlerをCloneします。
git clone https://github.com/builderio/gpt-crawler次にパッケージをインストールします。
cd gpt-crawler
npm installつづけてPlaywrightをインストールします。
npx playwright installここまでで環境構築は完了です。
②パラメーターをセットしてGPT Crawlerを実行
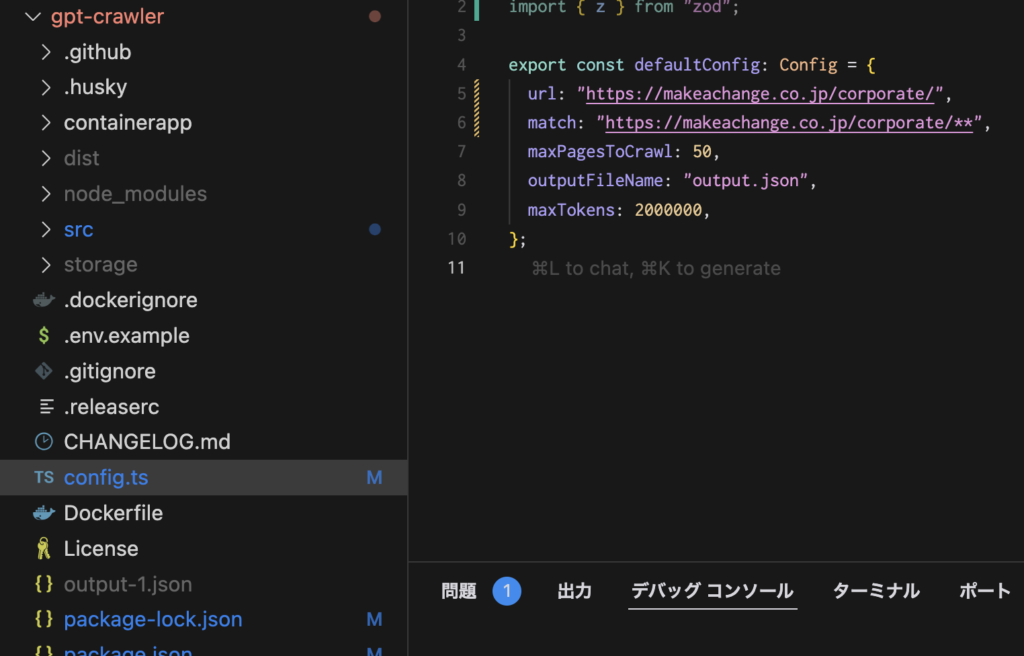
「config.ts」に読み込みたいURLなどのパラメーターを設定します。
export const defaultConfig: Config = {
url: "https://makeachange.co.jp/corporate/", // 読み込みたいURL
match: "https://makeachange.co.jp/corporate/**", // 読み込みたいファイルを指定
maxPagesToCrawl: 50,
outputFileName: "output.json",
maxTokens: 2000000,
};
いよいよ実行します
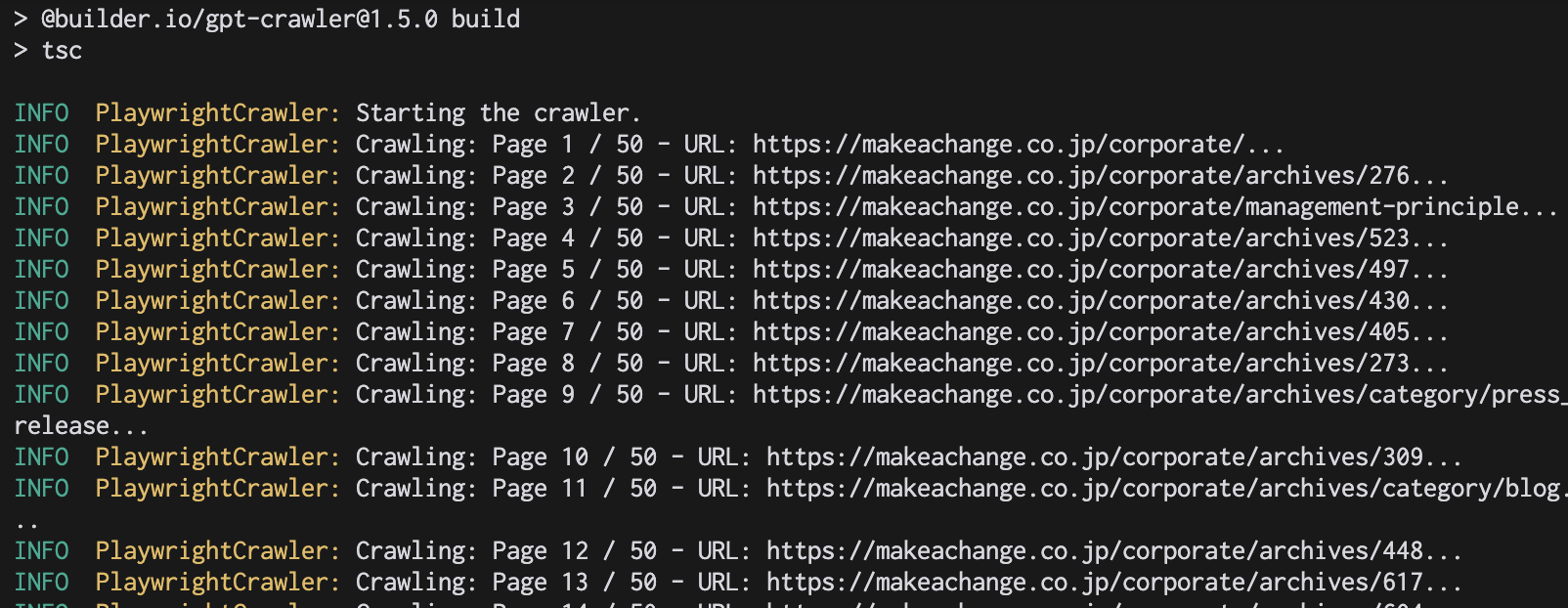
npm start実行するとURLからデータを読み込んでいることがわかります。
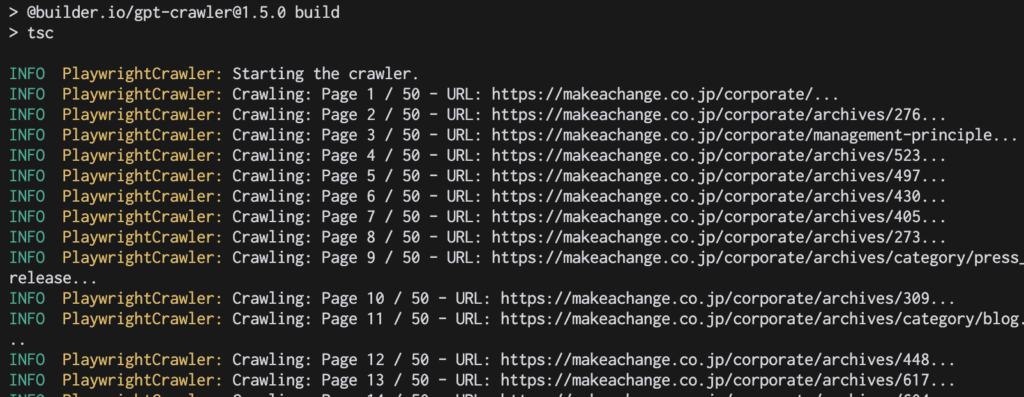
完了後、ルートフォルダ内に「output-1.json」というファイルが生成されていました。
③生成されたファイルをGPTsに設定
あとは生成されたJSONファイルをGPTsに設定して完了です。
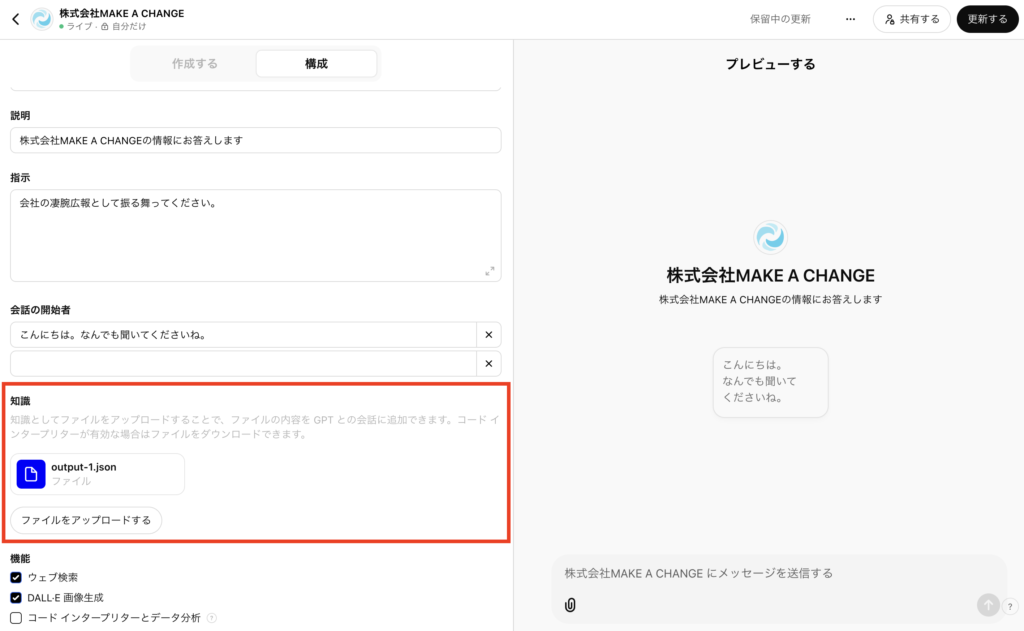
「知識」に生成したJSONを設定して完了です。
これで指定したURLの情報を学習したGPTsが作成されました。
まとめ
GPT Crawlerを使えば、手間のかかるデータ作成が驚くほど簡単になります。GPTsやDifyなどのツールと組み合わせることで、より高度なAIチャットボットを手軽に構築できます。
ぜひ、この便利なツールを活用してみてください。
おまけ
株式会社MAKE A CHANGEはAIシステム・アプリ開発とソリューションを提供する専門企業です。
お気軽にご相談ください。
また、生成AIに関わる仕事がしたい仲間(AIエンジニア、PM、UIUXデザイナーなど)も募集中です。


